用户在表单中填写信息后,这些信息最终是要提交到服务器上进行处理的。但是,并不是所有的信息都符合要求,我们需要在信息被提交到服务器之前,先对信息进行一下确认,来节约服务器端的系统资源,并提供良好的用户体验。正则表达式在信息验证中起着非常大的作用。
1. 什么是正则表达式?
正则表达式(regular expression / RegExp)是一个描述字符模式的对象。ECMAScript 的 RegExp 类表示正则表达式。
String 和 RegExp 都定义了使用正则表达式进行强大模式匹配和文本检索与替换的函数。
2. 创建正则表达式
创建正则表达式有两种方式,一种是采用 new 运算符,一种是采用字面量的方式。
2.1 new 运算符
RegExp 是 JavaScript 中的内建对象,所以可以用 new 操作符创建一个实例。
第一个参数是一个字符串,表示要匹配的字符模式;
第二个参数是模式修饰符(可选。不分顺序),表示前面的字符模式以怎样的方式进行检索匹配。
| 模式修饰符 | 含义 |
|---|---|
| i | ignoreCase 的首字母,表示忽略大小写 |
| g | global 的首字母,表示全局匹配 |
| m | multiline 的首字母,表示多行匹配,因为 g 全局匹配无法匹配到多行字符串中除第一行之外其他行的字符 |
2.2 字面量
上面那段代码中弹窗出来的 RegExp 实例,其实就是字面量的形式。我们可以将字面量写出来,跟用 new 操作符是一样的效果:
3. RegExp 和 String 拥有的关于正则表达式的方法
3.1 RegExp
RegExp 对象有两个方法:test() 和 exec() 方法,用于测试字符串匹配。
| 方法 | 功能 |
|---|---|
| pattern.test(str) | 接收一个字符串参数,在此字符串中进行字符模式的匹配,匹配到返回 true,否则返回 false |
| pattern.exec(str) | 接收一个字符串参数,在此字符串中进行字符模式的匹配,匹配到后返回一个 数组,数组中第一个元素是匹配到的字符串,如果有分组,后面的元素分别是分组的字符串。如果没有匹配结果则返回 null |
|
这两个方法都无需用 g 全局模式,用和不用都不影响结果,但是用的时候 pattern 的 lastIndex 属性值会变。
3.2 String
字符串有四个方法可以用到正则表达式来提高效率:
| 方法 | 功能 |
|---|---|
| str.search(pattern) | 返回匹配到的字符串在原字符串中开始的 index,没有则返回 -1 |
| str.match(pattern) | 返回一个数组,不开 g 全局,数组只有一个元素,是匹配到的第一个字符串;开 g 全局,数组可能有多个元素,是匹配到的所有字符串 |
| str.replace(pattern, str/func) | ❶用第二个参数得到的字符串,替换字符串中第一个参数匹配到的字符串,开 g 全替换,不开 g 只替换一个。❷如果第二个参数是一个函数,自动传入四个参数(最少,分组结果可能有多个),分别是 匹配到的字符串、 分组字符串、 匹配项的 index、 原字符串。❸我们需要在函数体中对这些参数处理一下,然后 返回一个字符串。❹每当有一个匹配结果时这个函数就被调用一次。 |
| str.split(pattern) | 返回一个数组,包含的是字符串按照指定 pattern 拆分的多个子字符串 |
|
4. 元字符
正则表达式元字符是包含特殊含义的字符。它们有一些特殊功能,可以控制匹配模式的方式。反斜杠后的元字符将失去原来的含义。
| 元字符 | 匹配情况 |
|---|---|
| . | 除换行符外的所有字符 |
| [a-z0-9] | 括号中字符集中的任一字符 |
| [^a-z0-9] | 任一不在括号中字符集中的字符 |
| \d | 任一数字 |
| \D | 任一非数字,相当于[^0-9] |
| \w | 任一字母或数字或_ 相当于[a-zA-Z0-9_] |
| \W | 任一非字母、数字和_ 相当于[^a-zA-Z0-9_] |
| \b | 一个词的边界 |
| \n | 换行字符 |
| \t | 制表符 |
| \r | 回车字符 |
| \s | 任何空白字符,包括空格、制表符、换页符等等 |
| \S | 非空白符 |
| ^ | 整个字符串的行首 |
| $ | 整个字符串的行尾 |
| x? | 0个或1个 x |
| x+ | 至少1个 x |
| x* | 任意个 x |
| (xyz)+ | 至少一个 xyz |
| x{n,m} | 至少 n 个至多 m 个 x |
| x{n,} | 至少 n 个 x |
| \1 或 $1 | 第一个分组中的内容 |
| \2 或 $2 | 第二个分组中的内容 |
| \3 或 $3 | 第三个分组中的内容 |
5. 贪婪和惰性
贪婪模式:当正则表达式中包含能接受重复的元字符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
惰性模式:意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。如果用它来搜索aabab的话,它会匹配整个字符串aab。
| 贪婪 | 惰性 |
|---|---|
| + | +? |
| ? | ?? |
| * | *? |
| {n,} | {n,}? |
| {n,m} | {n,m}? |
|
6. 前瞻
前瞻就是可以指定需要匹配的字符前面的字符,如果前面的字符不是指定的字符,那么就不算匹配到。
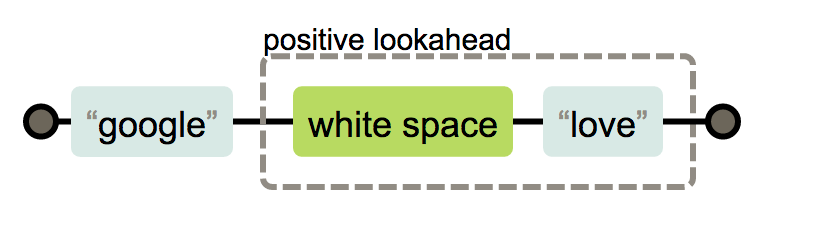
7. 常见的正则
7.1 检查邮政编码
邮政编码为6位数字,且首位不为0

7.2 检查文件压缩包
文件压缩包名称包括三个部分,包名、点号、压缩扩展名,包名可以包含的字符包括数字,字母和下划线:

7.3 删除多余空格
|
7.4 删除首尾空格
先删前面再删后面
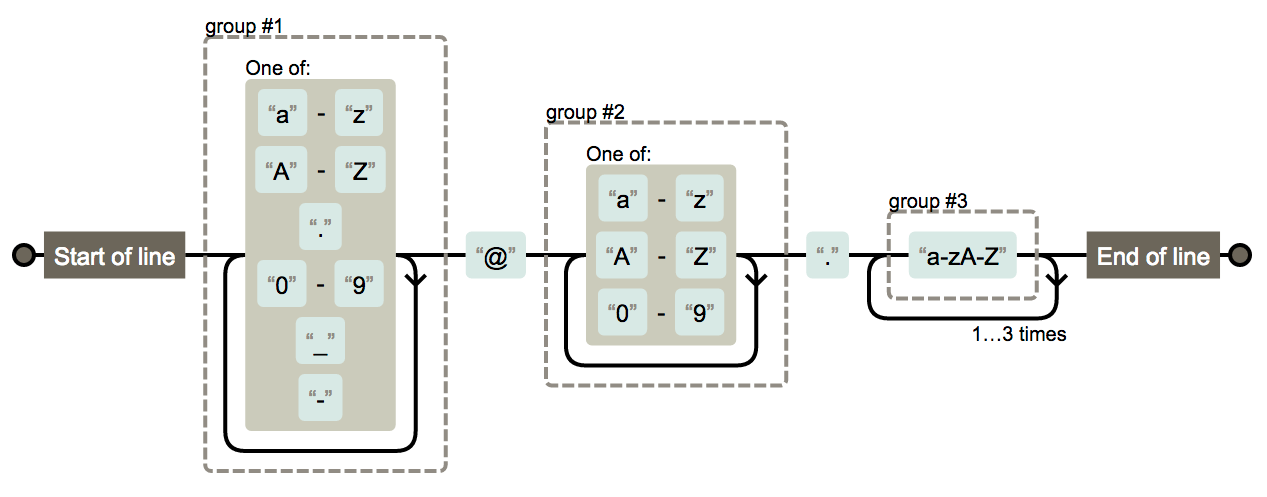
7.5 简单的电子邮件验证
邮箱一般有5个部分,用户自定义的,@,公司名称,点号,域名
本文参考:http://deerchao.net/tutorials/regex/regex.htm#greedyandlazy
可视化工具来自Regexper